Documentation Index
Fetch the complete documentation index at: https://docs.layercode.com/llms.txt
Use this file to discover all available pages before exploring further.
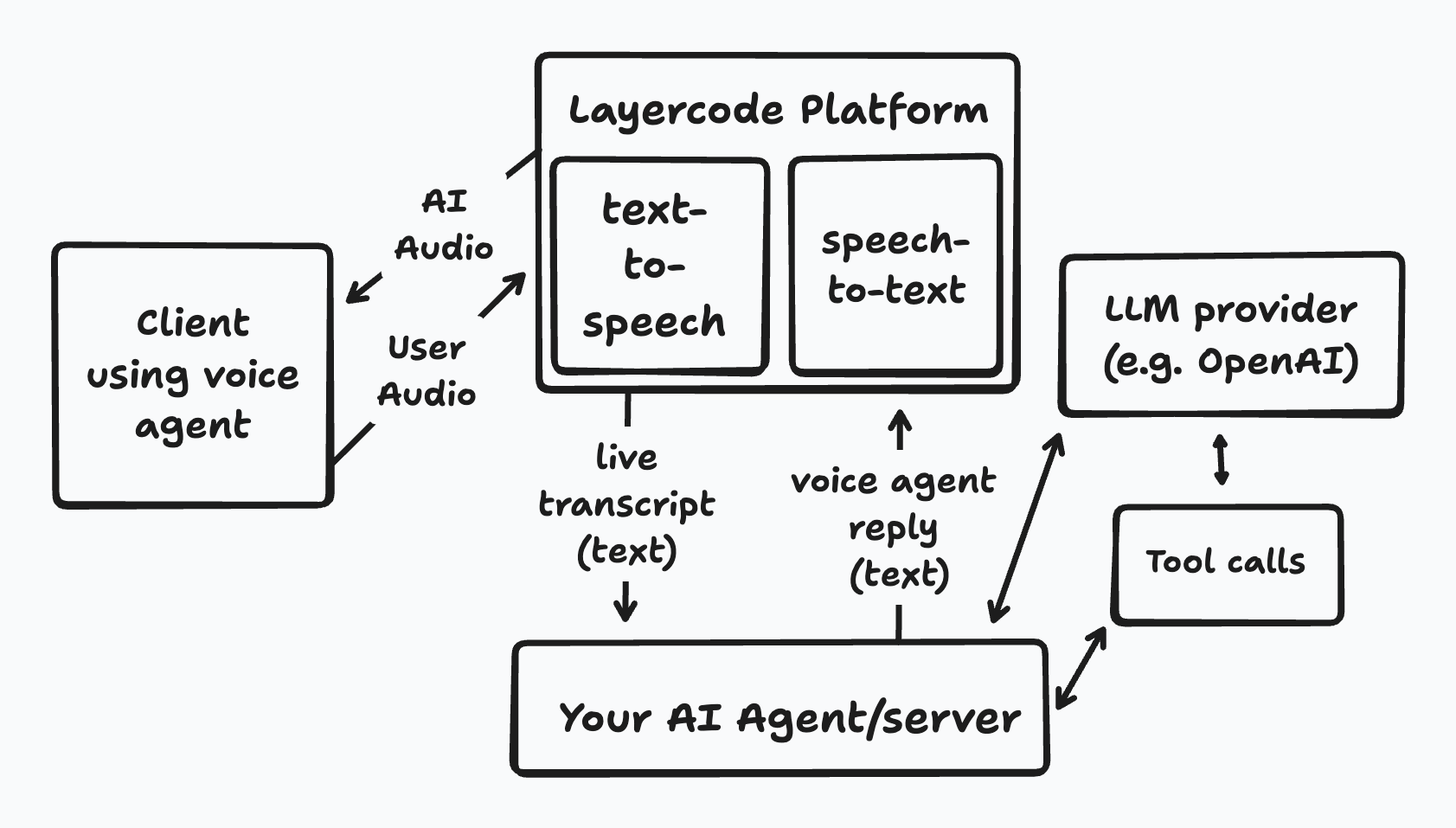
- Layercode captures the caller’s audio, runs speech-to-text (STT), and sends the transcribed text to your backend webhook.
- Your backend decides what to do — calling an LLM, tools, or business logic — and responds with the text you want the user to hear.
- Layercode turns that text into speech (TTS) and streams it back to the user in real time.
Authentication and Session Model
Layercode routes every client through an authorize → WebSocket handshake so you can govern sessions centrally.Client Authentication Flow
- Your frontend calls your backend (e.g.,
/api/authorize) with user context. - The backend requests
POST /v1/agents/web/authorize_sessionwithagent_idand the org-scoped API key. - Layercode returns a time-bounded
client_session_keyplus theconversation_id. - The frontend connects to
/v1/agents/web/websocket?client_session_key=...using the Layercode SDK.
Agent Webhook Flow
- Layercode sends signed POST requests (HMAC via
layercode-signature) to your webhook. - Verify requests with
verifySignaturefrom@layercode/node-server-sdkusingLAYERCODE_WEBHOOK_SECRET. - Handle events such as
session.start,message,session.update, andsession.end. Themessageevent includes the transcription and conversation identifiers. - Respond by calling
streamResponse(payload, handler)and emittingstream.tts(),stream.data(), or tool call results. Always callstream.end()even for silent turns.
Receiving messages from the client (user)
Every Layercode webhook request includes the transcribed user utterance so your backend never has to handle raw audio. A typical payload contains:Generating LLM responses and replying
Once you have a response string (or stream) from your model, send it back through thestream helper. You can optionally stream interim data to the UI while you wait on the final text.
Summary: what Layercode does and doesn’t do
What Layercode does
- Connects browsers, mobile apps, or telephony clients to a single real-time voice pipeline.
- Streams user audio, performs STT (Deepgram today, more providers coming), and delivers plain text to your webhook in milliseconds.
- Accepts your text responses and converts them into low-latency speech using ElevenLabs, Cartesia, or Rime—bring your own keys or use Layercode-managed ones.
- Manages turn taking (auto VAD or push-to-talk), jitter buffering, and session lifecycle so conversations feel natural.
- Provides dashboards for observability, session recording, latency analytics, and agent configuration without redeploys.
What Layercode doesn’t do
- Host your web app or backend logic — you run your own servers and own your customer state.
- Provide the LLM or agent brain—you choose the model, prompts, and tool integrations. Layercode only transports text to and from your system.
- Guarantee tool execution or business workflows — that remains inside your infrastructure; Layercode just keeps the audio loop in sync.
- Currently, Layercode does not support real time Speech to Speech models